Compétences
Outre la gestion de projets (relation client, recensement des besoins, livrables et gestion des délais) et la vulgarisation des solutions techniques mises en place, voici quelque une de mes compétences théoriques et téchniques.


Logiciels
DATAIKU
Dataiku est une plateforme de science des données collaborative qui simplifie le processus de travail sur les projets de données, de la préparation à l'analyse avancée. Son intérêt réside dans sa capacité à permettre une collaboration efficace entre les équipes, ce qui accélère le développement de solutions basées sur les données.
Son utilité n'est plus a démontrer et son principal (seul ?) inconvénient reste le prix des licences. J'ai pu me former, par les certifications proposées, puis pratiquer dans différentes entreprises avec cet outil pendant plus de 2 ans me permettant de le connaitre en profondeur et en détail. J'ai pu mener à bien des projets très variés, allant de la création d'un tableau de bord pour le marketing à la prédiction de captation magasin en direct, grâce à Dataiku.
TABLEAU
Tableau est un logiciel de visualisation de données qui permet de créer facilement des visualisations interactives à partir de différentes sources de données. Son principal intérêt se trouve dans sa capacité à transformer rapidement les données en informations exploitables, facilitant ainsi la prise de décision et l'identification des tendances.
L'autonomie des équipes métiers qu'apporte Tableau est un gain de temps certain pour tout le monde. Par le biais de Tableau j'ai pu rendre accessible en continu des informations cruciales pour une prise de décision rapide par les équipes business et produit. Les analyses récurrentes et KPI de suivis sont des chiffres clés à mettre dans un dashboard Tableau qui va par la suite faire gagner un temps précieux. J'ai eu l'occasion de travailler avec cette outil régulièrement durant les deux dernières années ce qui m'a permis par exemple d'intégrer un calcul automatique de la significativité et ainsi obtenir cette informations précieuse de manière automatique et visuelle.
SAS
SAS est une suite logicielle d'analyse de données qui offre une large gamme de fonctionnalités pour la manipulation, l'analyse et la visualisation de données. Ce qui fait sa force et sa faiblesse est le peu de flexibilité que SAS offre quant aux méthodes statistiques applicables. C'est en effet pour cela que certains milieux sensibles (finance, santé, etc.) le préfère car il est fiable sur les méthodes traditionnelles et connues.
J'ai pu pratiquer sur SAS régulièrement durant mes études et occasionnellement pour des clients, principalement pour la création de reportings automatisés pour le marketing, la direction financière ou les équipes produit directement.


Langages de programmation
Python
Python est un langage de programmation polyvalent et convivial, largement utilisé pour le développement web, l'analyse de données et l'intelligence artificielle. Son intérêt réside dans sa simplicité, sa flexibilité et sa grande communauté de développeurs.
La majeure partie de mes projets et réalisations implique ce langage de programmation qui est surement le plus répandu parmi les data scientistes et data analystes. En outre j'ai pu apprendre à faire des codes concis, efficaces, économes et bien commentés afin de les partager et de les rendre réutilisables. Que ce soit sur des notebooks Jupyter, d'autres éditeurs de notebooks, ou Dataiku j'ai beaucoup pratiqué et suis très à l'aise avec ce langage.
R, R Shiny
R est un langage de programmation populaire pour l'analyse statistique et la visualisation de données. Il est apprécié pour ses nombreuses bibliothèques spécialisées et sa syntaxe concise. R Shiny est un package de R qui permet de créer rapidement des applications web interactives à partir de code R, permettant aux utilisateurs de partager facilement des analyses de données ou de créer des outils d'analyse personnalisés pour une utilisation interne.
R est le deuxième langage le plus utilisé pour l'analyse de données et la modélisation statistique. A ce titre j'ai pu le pratiquer à de nombreuse occasion, notamment dans des secteurs où il est plus populaire comme la santé ou la recherche. J'ai également pu proposer des applications interactives grâce à R Shiny qui permet d'offrir un visualisation adaptée et accessibles rapidement aux utilisateurs.
SQL
SQL (Structured Query Language) est un langage de programmation utilisé pour gérer et manipuler des bases de données relationnelles. Son gros point d'intérêt se trouve dans sa capacité à interagir avec les bases de données de manière efficace en permettant aux utilisateurs d'effectuer des opérations telles que l'insertion, la mise à jour, la suppression et la récupération des données. SQL est largement utilisé dans le développement d'applications, la gestion de bases de données et l'analyse de données, ce qui en fait un outil essentiel pour la manipulation et l'interrogation des données stockées dans une base de données relationnelle.
C'est le langage de base de la programmation data, il est utilisable partout et offre une rapidité d'interrogation des base de données qui le rend très intéressant. Malgré tout il est très limité en terme de flexibilité de manipulation et de développement de méthodes statistiques, mais ce n'est ni son but ni son intérêt. Je l'utilise très régulièrement, soit directement soit imbriqué dans un autre langage de programmation.
SAS
Le langage de programmation SAS est le langage spécifique au logiciel SAS. Il permet, entre autres, de réaliser des projets data de bout en bout en interrogeant de manière efficace de larges bases de données. Sa gestion des grosses volumétries en fait un atout certain. Il hérite directement des qualités et des défauts du logiciel.


Méthodes statistiques
Tests statistiques
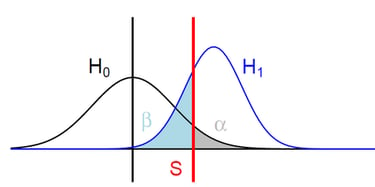
Je réunis sous cette appellation l'ensemble des méthodes et outils d'analyse de données qui ne sont pas de la modélisation. Cela représente donc un large spectre d'approches allant de la statistique descriptive (analyse univarié, analyse bivarié, box-plot, corrélations, etc.) à la comparaison de moyennes ou de proportions (variables qualitatives, quantitatives, grands échantillons, petits échantillons, paramétriques, non paramétriques, etc.).
Un exemple d'application qu'il m'a été donné de réaliser est un partenariat avec une chercheuse dans le médical. Pour la rédaction d'un article de recherche j'ai du rédiger et expliquer toute la théorie derrière les tests statistiques de comparaison de proportions, ainsi qu'adapter la méthodologie à des échantillons de petites tailles. Pour se faire j'ai réalisé plusieurs tests différents avec des hypothèses de départ différentes et j'ai croisé les résultats afin de ne garder que les significativités valides sur l'ensemble des tests.
Listes de tests déjà appliqués dans un projet : Test t de Student / Analyse de variance (ANOVA) / Test de Chi-2 / Test de Wilcoxon-Mann-Whitney / Test de exact Fisher / Test de Shapiro-Wilk / Test de corrélation de Pearson / Calcul de spécificité lexicale / etc.
Modèles de prédiction
Nous allons parler ici de prédiction à la fois de variables quantitatives (CA, stock, nombre d'appels au service client, etc.) et qualitatives (churn d'un client, cycle de vie, fraude, etc.). Ces modèles se basent principalement sur l'apprentissage du passé pour prédire l'avenir. Ils se composent de 3 grandes familles de modèles : l'ensemble des régressions (logistique, LASSO, etc.), les modèles de séries temporelles (AR, MA, ARIMA, Holt-Winters, etc.) et la partie Deep Learning avec les réseaux de neurones qui peuvent également être un outil poussant pour ce genre de problématiques (CNN, RNN, LSTM, etc.).
J'ai travaillé pour Autossimo sur leur gestion de stock et les besoins en nouvelles pièces. Pour se faire j'ai du travailler avec des algorithme d'apprentissage automatiques de la famille des régressions principalement afin de prédire le nombre de pièces nécessaire de tel ou tel type dans les mois à venir.
Listes de modèles déjà appliqués dans un projet : Régression linéaire multiple / Régression logistique / Régression multimodale / ARIMA / Holt-Winters / CNN / LSTM / Forêts Aléatoires / XGBoost / etc.
Modèles de classification
Les modèles de classification sont des modèles statistiques permettant de déterminer à quel "groupe" appartient un individu (individu = client, produit, magasin, etc.). Il existe 2 types de classification : la classification supervisée (qui revient aux modèles de prédiction car il s'agit de la classification dont on connaît déjà les classes que l'on veut en résultat et donc de la prédiction de variable qualitative.) et la classification non supervisée (lorsque l'on ne connait pas les groupes et que c'est justement ce que l'on aimerait déterminer). C'est cette deuxième catégorie que nous allons expliqué ici.
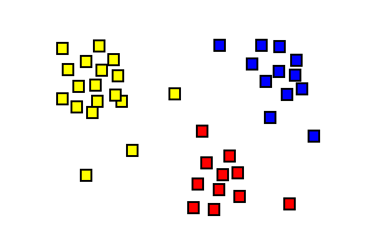
Ces méthodes sont utilisées pour découvrir des structures ou des groupes intrinsèques dans les données sans avoir de catégories prédéfinies. Elles sont souvent utilisées pour l'exploration des données, la segmentation du marché, la détection d'anomalies, ou encore la réduction de dimension. Cela permet, par exemple, de faire des segments de clients qui correspondent statistiquement à des caractéristiques communes et dont la connaissance de ces caractéristiques permet une approche Marketing plus personnalisée et efficace.
Une de mes expériences d'application de ces méthodes fut la classification des magasins d'une enseigne de grande distribution. Afin d'adapter l'assortiment et la communication de manière plus précise sans pour autant le faire de manière individuelle (extrêmement couteux), il leur fallait regrouper les magasins en une dizaine de groupes se rapprochant selon différents critères. J'ai donc travaillé sur ma base de données magasin en comprenant quels sont ces critères pour le métier et en appliquant une méthode de clustering répandue, le K-means, ce qui m'a permis de trouver les regroupements de magasins les plus optimaux par rapport à l'objectif.
Listes de modèles déjà appliqués dans un projet : K-means / CAH / Clustering mixte / Topic Modeling / etc.


Contact
youen.meyer@gmail.com
07 70 39 36 13